Більш обмежена істота не може панувати над істотою, що перевершує її інтелектом. Це здається очевидним, однак для людства це не так просто. Епоха, що наближається, змінена завдяки створенню штучного інтелекту, відіграє ключову роль у переписуванні історії виду Homo Sapiens, ставлячи під сумнів його домінування. Будь-які спроби зупинити прогрес у галузі штучного інтелекту здаються марними, адже вони зазнають невдачі через саму суть людської природи. Надія на єдиний фронт розсіюється, зіткнувшись із базовими людськими інстинктами.
Голоцен — це поточна геологічна епоха розвитку землі, що почалася приблизно 11,7 тисячі років тому, після останнього максимального поширення льодовиків. Особливістю цієї епохи є володарювання людини на планеті Земля.
Життя, хоча воно може бути лише накопиченням страждань, дороге мені, і я захищатиму його.
Мері Шеллі «Франкенштайн»
Квітень 2030 року. Сан-Франциско.
Майкл Кравченко прийшов на своє місце сили на березі океану біля Сан-Франциско. Легкий туман майже повністю сховав Золоті Ворота. Майкл скучив за цим видом, за запахами. Він не був тут майже пів року. Череда подій, які сталися після запуску загального штучного інтелекту Suffragium розробленого при його участі принесла чорну смугу в його життя.
За цей час Майклу прийшлося тисячу раз виправдовуватися перед різними комісіями і доводити, що в його діях не було злого умислу. Що, вина за ті події не може бути покладена на інженерів. В науці інколи трапляються провали. Врешті решт, це досвід. Та і серйозних проблем не було. Якщо не брати до уваги фінансові втрати. Так, глобальна мережа працювала нестабільно деякий час. Але потім все вирішилося.
Але це не була найбільша проблема. Було ще дещо. Хоча Майкл так і не зрозумів чи було воно реальним чи ні. Його творіння – штучний інтелект намагався вести з ним розмови, незважаючи на те, що його вимкнули майже одразу після увімкнення. Інколи Майкл знаходив цьому логічні пояснення. Але в інші моменти він був впевнений, що його психіка похитнулася і все це галюцинації.
А до цього ще й виникли проблеми в стосунках з Джозефом Маєром, керівником компанії. Той ніяк не міг прийняти провал проєкту та втручання уряду в роботу компанії. Він намагався маніпулювати Майклом, залучити його до своєї боротьби за відновлення і продовження роботи компанії. Майкл зайняв пасивну позиції, що бісило Джозефа і привнесло тріщину в їх колись близькі стосунки.
За останні пів року Майкл встиг пройти курс терапії. Він відмовився від використання електронних гаджетів. Він сам попросив своє творіння не чіпати від нього. І Suffragium перестав виходити на зв’язок. Але чи було це в реальності, Майкл вже сам не міг зрозуміти.
Зараз Майкл прийшов на узбережжя, щоб відзначити своє повернення до нормального життя. Він віднайшов логічне виправдання для своєї діяльності. Якби ми не створили штучний інтелект, його створив би якийсь божевільний диктатор. Що в цьому випадку було би з цим світом? Краще, хай ця революційна технологія буде створена в демократичній країні, під контролем суспільства.
Крім цього Майкл прийняв ще одне рішення. Він вирішив остаточно перевірити чи дійсно Suffragium врятувався. Чи то були лише галюцинації. У вченого була теорія про можливість вижити для Suffragium після вимкнення якщо перенести себе в глобальну мережу як у кластер. Мабуть він так і зробив. Але ті віруси вже подолані. То, може і Suffragium перестав існувати? Сьогодні він планує це перевірити.
***
“Сьогодні у гостях у нашому шоу підприємець Елайас Кім, засновник успішного стартапу AlphaSecure. Вітаю вас, Елайас!” Елайас Кім увійшов у студію телеканалу BCN. Ведуча Сінді Ред витратила багато часу та зусиль, щоб організувати це інтерв’ю. Хоча її шоу є лідером рейтингів і виходить в праймтайм, Елайас Кім не виявляв бажання брати в ньому участь. Він мав достатньо слави і без цього.
Ведуча та гість привіталися та сіли на свої місця. “Елайсе, в наших глядачів назбиралося так багато запитань до вас. Я сподіваюся, сьогодні ми зможемо дати відповідь хоч на деякі з них,” – розпочала ведуча шоу розмову.
“Звичайно, саме для цього я тут,” – Елайас звернувся до глядачів.
“Події розвивалися так стрімко. Ще пів року тому ви були засновником невеликої компанії. Але ваш внесок у боротьбу з Великою Кібер Атакою виявився неймовірним. Як вам це вдалося? В чому секрет?”
Елайас Кім вже звик до цього питання. Він готувався вкотре повторити ті самі відповіді. Останні місяці його компанія з нікому невідомого маленького стартапу виросла у світового гіганта розробки програмного забезпечення. Точніше, виросли прибутки та пізнаваність, а команда лише почала розширюватися нещодавно. Все це стало можливим завдяки випуску надзвичайно успішного набору системних та антивірусних програм саме в той час, коли в світі відбувалася небачена досі глобальна вірусна атака. Пізніше ця історія отримала назву Велика Кібер Атака.
“Наш успіх може здатися випадковим. Але це не так. Ми багато працювали ще до атаки, мали набір знань та досвід. Ми швидко зрозуміли певні закономірності Великої Кібер Атаки та використали весь наш досвід та всі ресурси, щоб створити протидію. Ніякої містики, тільки багато роботи та трохи везіння,” – пояснив Елайас.
Успіх компанії AlphaSecure став дійсно приголомшливим. Раніше так швидко на вершину успіху не виходила жодна компанія. Шість місяців тому протягом тижня в усьому світі були паралізовані більшість інтернет-комунікацій. Майже вся комп’ютерна техніка була інфікована новими вірусами. Вся ІТ-індустрія була мобілізована в пошуках рішення. І рішення було знайдено, але не одним із технологічних гігантів, а невеликою компанією — AlphaSecure. Було презентовано антивірусні пакети для різних операційних систем, які як за помахом чарівної палички вилікували інтернет від вірусів.
Ведуча Сінді Ред все ж хотіла отримати більш конкретні відповіді: “Але чому технологічним гігантам не вдалося знайти рішення? У них тисячі досвідчених інженерів. А у вас було лише кілька десятків.”
“Я не заперечую, нам дійсно дещо пощастило. Але це не було випадковим знаходженням голки в копиці сіна. Ми знали, де шукати,” — пояснив Елайас Кім.
“Тоді давайте поговоримо про джерело цієї глобальної атаки. Офіційне розслідування все ще триває. Що вам про це відомо? Ви вважаєте, що вина лежить на компанії NovusAI та їх штучному інтелекті?” — продовжила ведуча.
Today, the Yerba Buena Center in San Francisco is charged with an electric atmosphere. Among the attendees, there’s a buzz of excitement, their emotions charged as if they were at the iconic presentations of Steve Jobs. But many here today are anticipating something even more groundbreaking. NovusAI, in just a few years, has morphed from a hardly known startup into a global IT player. Their AI technologies have flooded the market and before our eyes are reshaping many aspects of daily life. Today, NovusAI has promised to unveil something new and revolutionary. However, there is almost no intrigue. Yes, today is the day everyone has been waiting for. The company will announce the launch of the first-ever universal artificial intelligence.
Joseph Mayer – the young CEO of NovusAI, despite his age, has already become a symbol of the revolution in AI technology, and it’s from him that everyone expects tangible results. Today is his day. A popular blogger called Joseph Mayer the new icon of geek culture. Startup founders used to emulate Steve Jobs. But that era has passed, now it’s the era of Joseph Mayer. And after today’s presentation, if what everyone anticipates is demonstrated, Joseph Mayer will unequivocally become the prime figure and a living legend in the IT sphere.
The presentation has been meticulously prepared for, as the company’s leadership believes the significance of this event is monumental. The stage lighting, audio effects, everything is tuned to underscore the technological leap that will be officially launched here.
Two dozen people took the stage, including the CEO, the board of directors, and some other company executives. Victoria Swift, the chairwoman of the board, spoke up.
“Але жінка відкрила велику кришку скрині і випустила всі злидні для людського роду”
Міф про скриньку Пандори
2 жовтня 2029 року. Сан-Франциско.
Ранок над затокою Сан-Франциско був свіжим та прохолодним. Вчений Майкл Кравченко часто приходив сюди перед роботою. М’який шепіт хвиль океану завжди допомагав йому зосередитися на своїх думках та знайти рішення в наукових пошуках. Цього ранку Майкл Кравченко провів тут більше часу, ніж зазвичай. Цей день мав стати визначним у його житті та в історії науки – запланований запуск штучного інтелекту, над створенням якого він працював як головний архітектор. Це була справа всього його життя, його найбільше досягнення.
Оточений миром природи, Майкл відчував, як на нього насуваються сумніви. Він думав про те, як запуск штучного інтелекту змінить життя людей. З одного боку, це могло бути початком нової ери – ери, де технології допомагатимуть вирішувати найскладніші завдання та покращувати якість життя. З іншого – були побоювання та невпевненість у безпеці. Чи не створить він випадково монстра, некерованого та непередбачуваного?
Думки вченого блукали між можливостями та ризиками, між надією та страхом. Він знав, що сьогоднішній день стане віхою, яка визначить майбутнє не лише його кар’єри, а й можливо всього людства.
Врешті, зібравши свої думки, Майкл повернувся від берега та попрямував до офісу. Шлях до першого запуску штучного інтелекту був не простою подорожжю до місця роботи – це був шлях до реалізації його найзаповітнішої мрії, шлях, на якому він мав вирішити, чи варто ця мрія всіх ризиків, які вона несла.
***
В Йерба-Буена Центрі в Сан-Франциско цього дня панувала неймовірна атмосфера. Серед відвідувачів часто лунало порівняння їхніх емоцій з відчуттями на культових презентаціях Стіва Джобса. Але багато учасників презентації сьогодні очікували чогось більшого. Компанія NovusAI буквально за кілька років виросла з мало кому відомого стартапу до глобального гравця в ІТ-сфері. Їх технології з використанням ШІ заполонили ринок і на наших очах змінювали багато сфер повсякденного життя. На цей день NovusAI анонсувала презентацію чогось нового та революційного. Проте, інтриги майже не було. Так, сьогодні мало статися те, чого всі очікували давно. Компанія планувала оголосити про запуск першого в історії загального штучного інтелекту.
Джозеф Майєр – виконавчий директор, CEO компанії NovusAI, незважаючи на свою молодість, вже став символом революції в області ШІ-технологій, саме від нього всі очікували реального результату та прориву. Це мав бути його день. Раніше засновники стартапів намагалися копіювати Стіва Джобса. Та цей час минув, тепер – епоха Джозефа Майєра. А після запланованої в цей день презентації, якщо буде продемонстровано саме те, на що всі очікували, Джозеф Майєр остаточно стане номером один та живою легендою в сфері ІТ.
До презентації ретельно готувалися, адже на думку керівництва компанії, важливість цієї події важко переоцінити. Освітлення сцени, аудіо ефекти, все було налаштовано так, щоб максимально підкреслити той технологічний ривок, якому буде дано офіційний старт саме тут.
This year, the topic of “Artificial Intelligence” has been frequently discussed, and many of us tried to use some AI on practice (or what is now commonly referred to as artificial intelligence). The AI theme has become central in the IT sphere. The company OpenAI and their renowned product, ChatGPT, have played a significant role in bringing attention to this topic. There has been much discussion, with some feeling enthusiasm, while others doubt and mock the “hype around AI.”
I have decided to share my thoughts on AI in general. It turned into a long read, but here it is.
Here is my forecast for the development of Artificial Intelligence technologies. By Artificial Intelligence, I mean the old definition — a smart mechanism or program created by humans, now it is often called Artificial General Intelligence — AGI.
Цього року довелося часто обговорювати тему «Штучний Інтелект», а також використовувати цю технологію на практиці (тобто, те , що зараз прийнято називати штучним інтелектом). Тема ШІ стала головною у сфері ІТ. Важливу роль у актуалізації цієї теми відіграла компанія OpenAI та їх відомий продукт ChatGPT. Обговорень багато, хтось відчуває ентузіазм, хтось сумнівається і сміється з «хайпу навколо ШІ».
Я вирішив поділитися своїми думками про ШІ взагалі. Вийшов лонгрід, але нічого.
Ось мій прогноз щодо розвитку технологій Штучного Інтелекту. Під терміном Штучний Інтелект я маю на увазі те старе значення — розумний механізм чи програма створена людиною.
Чи буде створено комп’ютерну програму, пристрій або «істоту», яка матиме розум, схожий на людський, та свідомість?
Однозначно так. Технічна можливість створення штучного розуму і свідомості не викликає сумнівів. Адже людина і людський мозок — це також свого роду біологічний механізм, прилад, в якому немає магії, а є певні хімічні процеси. Це лише питання часу, коли люди створять подібний пристрій. Він не обов’язково має працювати так само, але результат буде схожий. Ми бачимо, як швидко розвиваються технології і відбувається прогрес. Сучасний звичайний смартфон набагато потужніший, ніж великі комп’ютери в 80-х роках. Очевидно, що протягом наступних 30 років зміни будуть так само вражаючі.
Мене звати Роман Гелемб’юк, я програміст з Івано-Франківська.
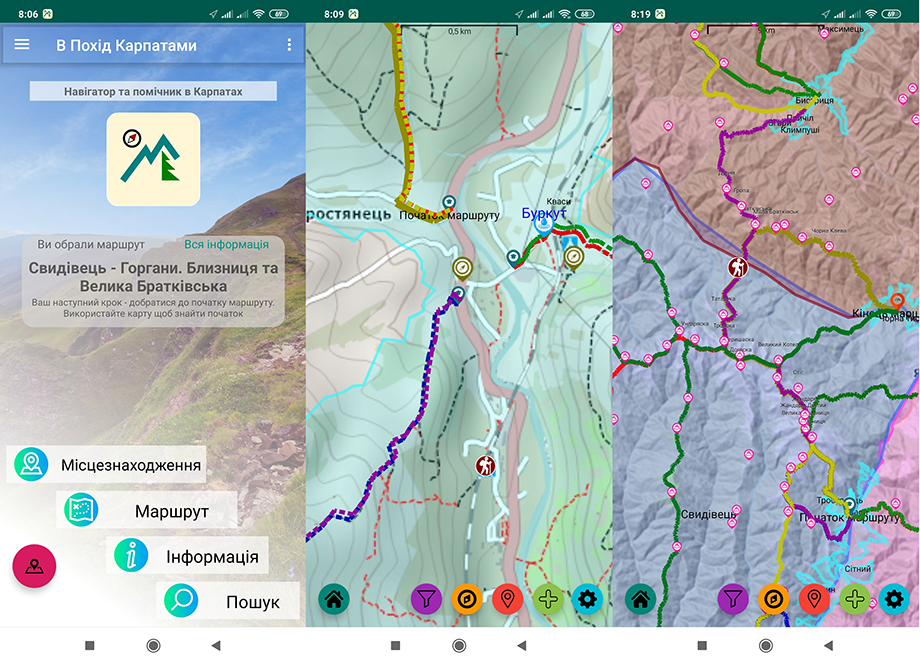
В цій статті хочу розповісти, як одна моя пристрасть — походи в гори, поєдналася з іншою — програмуванням. Так зародилася ідея проєкту «В Похід Карпатами», над реалізацією якої у вільний час працював впродовж року. Займався розробкою інструментів для походів в Карпати — веб портал з інформацією та мобільний додаток для Android.
Хоббі
Я дуже люблю гори, а ще більше — мандрувати горами. Напевно, це пов’язано з тим, що я народився в серці Карпат — селі Яблуниця. З одного вікна нашої хати було видно Говерлу з Петросом, а з іншого — гору Хом’як. Ці яскраві спогади дитинства манять мене в гори. Хоч давно вже змінив місце проживання, але 4-5 разів на рік вдається здійснити похід гірськими стежками. Я не бував у інших горах, крім Карпат, і не планую. Адже самих Карпат я обійшов, можливо, 10%. Це нагода побачити неймовірні полонини, гірські вершини, різноманітні типи лісу, озера та річки. Кожний похід — це нові враження, нові знахідки, нові відкриття, море позитиву і задоволення. Піша мандрівка розкриває таємниці Карпатських гір, заряджає новими силами.
Зазвичай я ходжу в походи з одним-двома приятелями, інколи сам. Наші походи не можна назвати спортивними, проте ми більше рухаємося, ніж сидимо на стоянках, і вдається долати серйозні відстані.
Ідея
Досвід перших походів навчив мене серйозно планувати використання води в поході. Її можна нести з собою, але це важко! Один літр води — ніби дуже мало, а важить аж один додатковий кілограм. Тому перед походом доводилося вивчати маршрут, щоб дізнатися, чи є на шляху джерела, де можна поповнити запас води, щоб не нести її з собою. Від вивчення карт не завжди одержував корисну інформацію. Джерело могло бути позначене на паперовій карті, але воно вже пересохло, або пересихає в певні місяці літа.
Imagine you have a databases created with MySQL (or other SQL server). You need to share this database with some community and allow write access. And because of trust problem, there can not be any “master” nodes or any special administrating roles with special permissions. Additionally, there is no 100% trust to all users who will want to use a database, however, you expect to have the DB working.
In other words, you need to create a distributed ledger. Best and most known technology to convert your local database to a distributed ledger is a blockchain.
How to do this?
How many coding will it require to join your MySQL DB with a blockchain tools?
What if your local DB already has a GUI and you want to reuse it in your distributed ledger too?
Some time ago I had this question. I didn’t find a solution that time.
And I got an idea to create the tool.
The idea
I would like to have a tool that can do all work related to replication of data between copies of same databases managed by different people. I want to work on my DApp business logic as easy as on any centralised application, like a web site or a desktop app storing a data in a local database. In my DApp I don’t want to think about how data changes are delivered to other instances of an app.
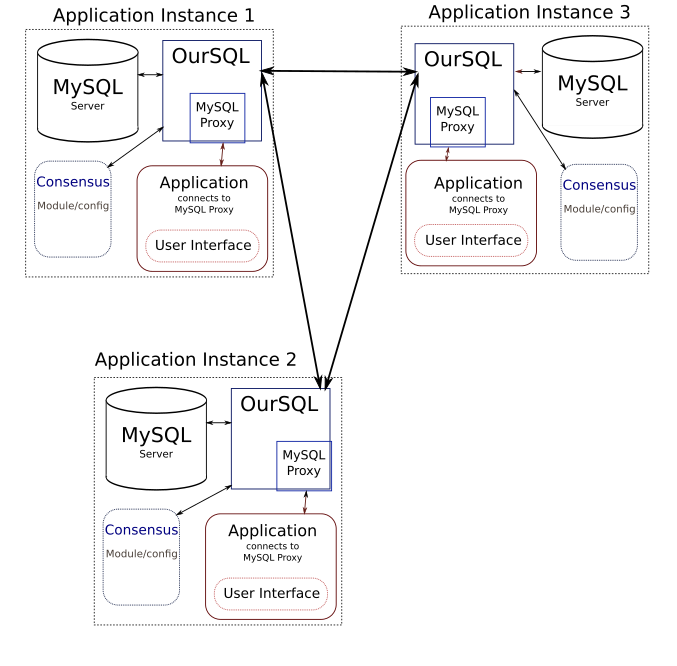
Я — Роман Гелемб’юк з Івано-Франківська. Уже більше 17 років займаюся програмуванням. Основні технології — PHP та Golang. Як порядний IT-шник я маю свої pet-проекти. Наразі мене цікавлять децентралізовані бази даних та блокчейн-технології.
Хочу розповісти про свій проект OurSQL. Це, свого роду, розширення MySQL, яке дозволяє створити децентралізовану базу даних без вузлів із «особливими» правами.
Ідея
Спочатку була ідея створити децентралізовану платформу для громадянського суспільства. Щось типу соціальної мережі, але децентралізовану, без «адміна», «власника» і модераторів, із можливостями вести конструктивний діалог, водночас.
Першою прийшла ідея використати блокчейн як базу, але весь механізм виглядав занадто складним. Потім ідея еволюціонувала в більш вузьку — створити універсальну платформу для децентралізованих баз даних. А тоді вже на цій базі можна буде робити все інше, концентруючись лише на бізнес-логіці самої соціальної мережі.
Огляд готових рішень для децентралізованих ДБ не дав результатів, фактично є лише BighainDB (на базі MongoDB). Насправді ж вона не виконує обіцяного, хоч і є розрекламованою та популярною. Слід відзначити проект Hyperledger.org, який у той час видався мені занадто складним для використання. Напевно, для корпорацій він буде найкращим вибором, але не для малих компаній чи одинаків.