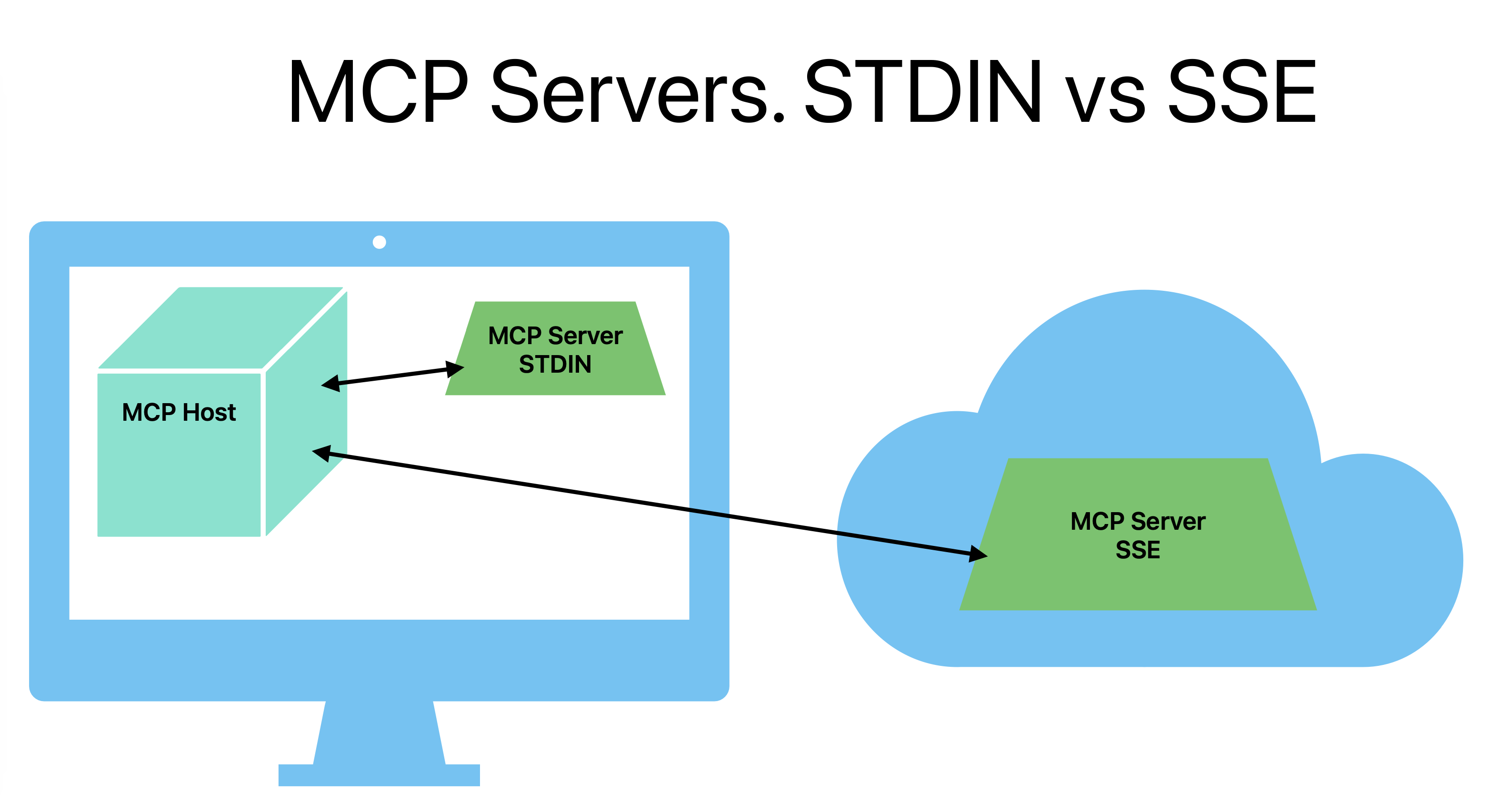
Implementing memory for AI assistants or conversational AI tools remains a complex engineering challenge. Large Language Models (LLMs) like ChatGPT are stateless by design—they only retain knowledge up to their training cutoff and do not inherently remember past interactions. However, for a seamless and context-aware user experience, it’s crucial for AI chat tools to recall previous conversations, preferences, and relevant history.
To address this gap, different vendors have developed their own proprietary solutions for integrating memory. For example, OpenAI’s ChatGPT has built-in memory capabilities, and other platforms like Anthropic’s Claude (including the Claude Desktop application) offer similar features. Each of these implementations is unique, often tied closely to the platform’s internal architecture and APIs.
This fragmented landscape raises an important question: what if we had a standardized way to implement memory for AI assistants?
Model Context Protocol (MCP) was originally designed to provide a standard way to integrate external tools with large language models (LLMs). But this same concept could inspire a standardized approach to implementing memory in AI chat systems. Instead of inventing something entirely new, perhaps we can extend or repurpose MCP to serve this function as well.
Let’s explore whether this could work.
Before that, however, it's important to understand how memory currently works in AI chat platforms like ChatGPT. The truth is, we don’t have access to the exact implementation details—these are proprietary systems. But we can make some educated guesses about how such a system might be structured.
At a high level, there is likely a dedicated memory subsystem responsible for tracking and storing information over time. Every user prompt and each AI response could be sent to this subsystem, which then processes the data to extract key facts—such as recurring interests, important context, and user preferences. These details are distilled and saved as a kind of internal profile or knowledge base about the user.
Then, when a user returns to continue a conversation, the memory subsystem can generate a contextual "snapshot" of the most relevant information. This memory snapshot is appended to the prompt or included in the context window before the next request is sent to the LLM, allowing the assistant to maintain continuity and personalization across sessions.
If this architectural pattern is indeed common, MCP could provide a unified protocol to formalize this interaction: how memory is updated, how snapshots are requested, and how information is exchanged between components. This could enable AI systems from different vendors to adopt compatible memory models, improve interoperability, and promote best practices.
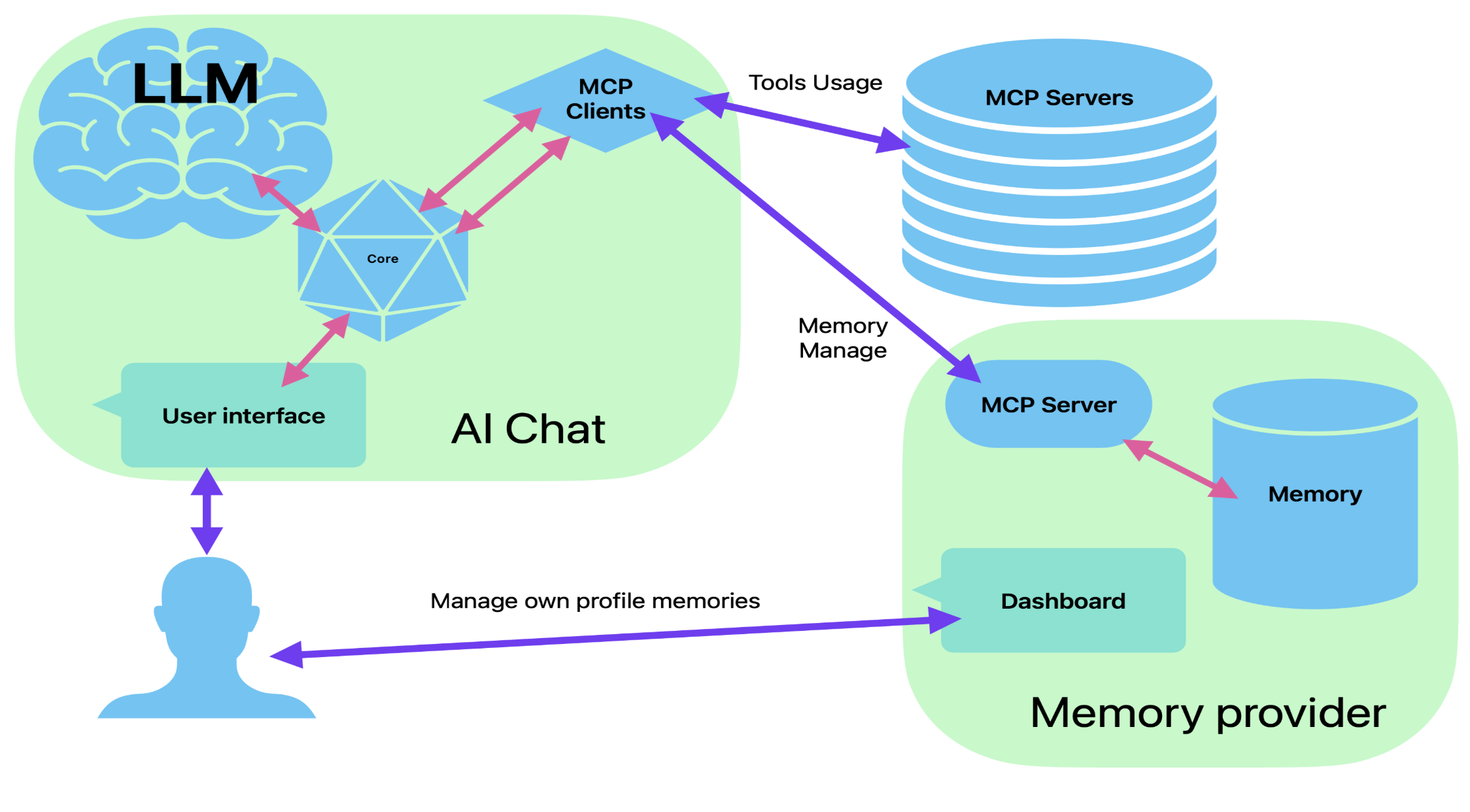
Proposed Interface for Using MCP Server as a Memory Subsystem for AI Chat
Integrating long-term memory into AI chat systems is essential for creating a more personalized and coherent user experience. By leveraging the Model Context Protocol (MCP), we can define a standardized interface for memory integration that can work across different LLM-based systems.
Below is a proposed design for how an MCP-compliant memory subsystem could function as part of an AI chat application.
1. Recording Prompts and Responses
To build and maintain memory, the system must record all user inputs (prompts) and AI responses. This allows the memory server to extract relevant information, identify important patterns, and update long-term memory accordingly.
tool: memory/prompt
Args:
- prompt: string
tool: memory/response
Args:
- response: string
Both prompts and responses should be sent in real-time as they are generated. This enables the memory subsystem to incrementally build a profile of the user and the ongoing conversation.
2. Retrieving Summarized Memory Data
Before submitting a prompt to the LLM, the AI chat system should request a summarized snapshot of the user’s memory. This summary provides essential background context and ensures the model has the necessary information to maintain continuity and personalization.
resource: memory/summary
Args:
- context_window: int
This is the most critical component of the memory interface. It should return a structured summary that combines:
- Long-term facts: Persisted knowledge about the user (e.g. interests, preferences, goals).
- Recent context: Short-term memory of the latest conversation turns or topics.
The structure of this memory summary must be carefully designed to fit within the token constraints of the model while maintaining relevance and clarity.
3. Memory Search and History Retrieval
Beyond automatic summarization, the AI assistant may occasionally need to search the memory history—for example, to check whether a specific topic has been discussed before, or to retrieve past details on demand.
Full-Text Search Across Memory
resource: memory/search
Args:
- query: string
This allows the system to look up prior messages (prompts/responses) that match a search query, enabling deeper context exploration when needed.
Fetching History Around a Specific Message
resource: memory/fetch
Args:
- message_id: string
- prev_count: int
- next_count: int
This retrieves a focused history fragment, including the specified message and a number of surrounding messages. It helps in reconstructing the full context of a past discussion.
Background Processing and Real-Time Efficiency
In practice, most of the heavy lifting—like memory summarization, relevance scoring, and topic modeling—should be handled asynchronously in the background by dedicated workers.
The main memory interface, as described above, is designed for performance and responsiveness:
- Prompt/response logging is immediate and lightweight.
- Memory summary retrieval returns precomputed data, ready to inject into the LLM prompt.
- Search and fetch operations can be optimized using indexed storage and preprocessed metadata.
By offloading intensive processing to background jobs, the system ensures low-latency responses while maintaining rich and evolving user memory.
Extending AI Chat Architecture to Use MCP for Memory
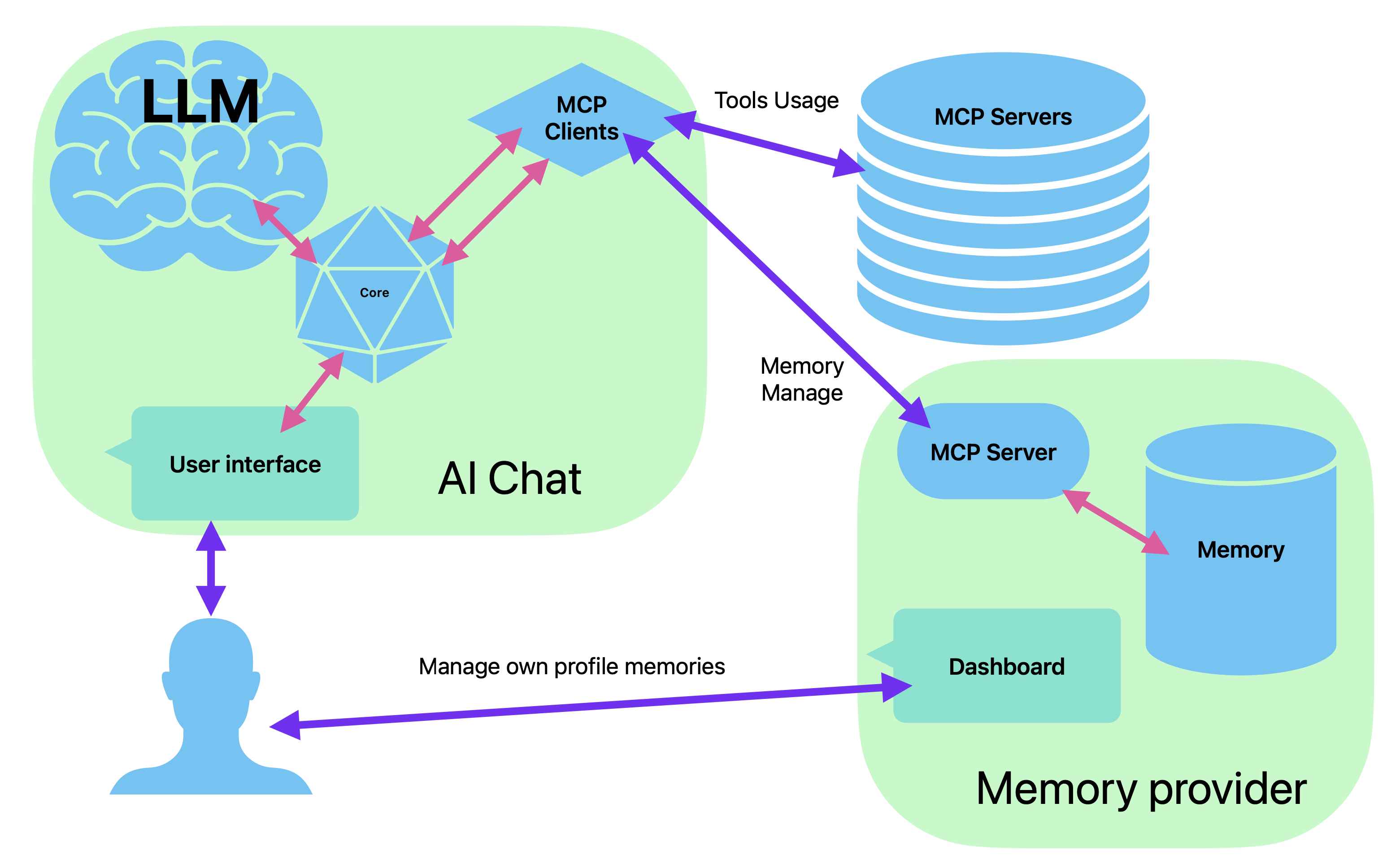
The proposed MCP-based memory server fits well within the Model Context Protocol framework. However, there’s one key challenge: tool calls in MCP are typically initiated by the LLM—and this model doesn't work well for memory management.
In some current implementations, users are expected to prompt the LLM with special instructions like, “Please call the memory tool after each response,” either before or after each message. This is cumbersome and unreliable. The assistant might forget, misunderstand, or misuse the memory tool altogether.
This is not the right direction.
Instead, memory integration should be hardcoded into the AI chat application itself—at the system level. Here's how this could work:
- When a user sends a prompt, the chat client must automatically call
memory/prompt. - Before sending that prompt to the LLM, it must call
memory/summaryand inject the returned data into the context window. - After receiving a response from the LLM, the client must call
memory/responseto record it.
These operations should be mandatory and transparent to the LLM. This ensures memory consistency, reliability, and simplifies prompt design for end-users.
Other memory-related features—like searching the history or retrieving older conversations—can remain under LLM control as standard MCP tools. The model can invoke them when it determines they’re needed.
Benefits of This Architecture
This architecture introduces a significant opportunity to transform how memory is handled in AI systems. Below are several powerful benefits:
1. Memory Becomes a Separate, Interchangeable Service
AI memory is no longer bound to a specific AI chat provider. You can use a chat interface from one company, but have your memory managed by another. This separation of concerns fosters a healthier ecosystem, allowing users to choose the best provider for memory storage, summarization, and insights.
2. You Can Change Memory Providers at Any Time
Since all memory services implement the same standard MCP interface, they become interchangeable. If a new provider offers better summarization, improved privacy, or smarter context handling, you can switch—just like changing email apps or cloud storage providers.
3. You Can Switch AI Chat Tools Without Losing Your History
Imagine using ChatGPT for a year, and then deciding to switch to Claude because it now has a better model. With this architecture, you simply disconnect your memory from ChatGPT and reconnect it to Claude. All your history and personalized memory comes with you—portable, persistent, and platform-independent.
4. One Memory, Multiple Assistants
You might use different AI assistants for different tasks—ChatGPT for writing, Claude for coding, and another on your smartphone for everyday queries. With a shared memory provider, all these assistants can access and contribute to the same personal memory. You get a unified assistant experience, regardless of which tool you’re using.
5. Full Transparency and Control Over Your Memory
A standalone memory provider can also offer a user-facing interface—a secure dashboard where you can:
- View your complete AI conversation history
- Review and edit the AI’s summarized memory and insights
- Delete messages or specific facts you don’t want stored
- Control how your memory is used across different assistants
This puts users in control of their data, promoting trust, transparency, and autonomy.
This approach turns memory into a first-class, user-centric service—independent, interoperable, and customizable. It unlocks a future where users own their history, assistants collaborate more intelligently, and AI ecosystems become modular and competitive.
🧠 Summary: Using MCP Server as a Memory Subsystem for AI Chat
In this article, we explore how the Model Context Protocol (MCP)—originally designed for tool integration with LLMs—can be reused to standardize AI memory handling across chat systems.
🔧 Key Idea
Rather than letting the LLM decide when to call memory-related tools, we propose hardcoding memory interactions at the AI chat system level. This ensures consistent and reliable memory operations, independent of the model’s reasoning or prompt instructions.
This architecture promotes modularity, portability, and user control—paving the way for a more open, personalized, and interoperable AI ecosystem.