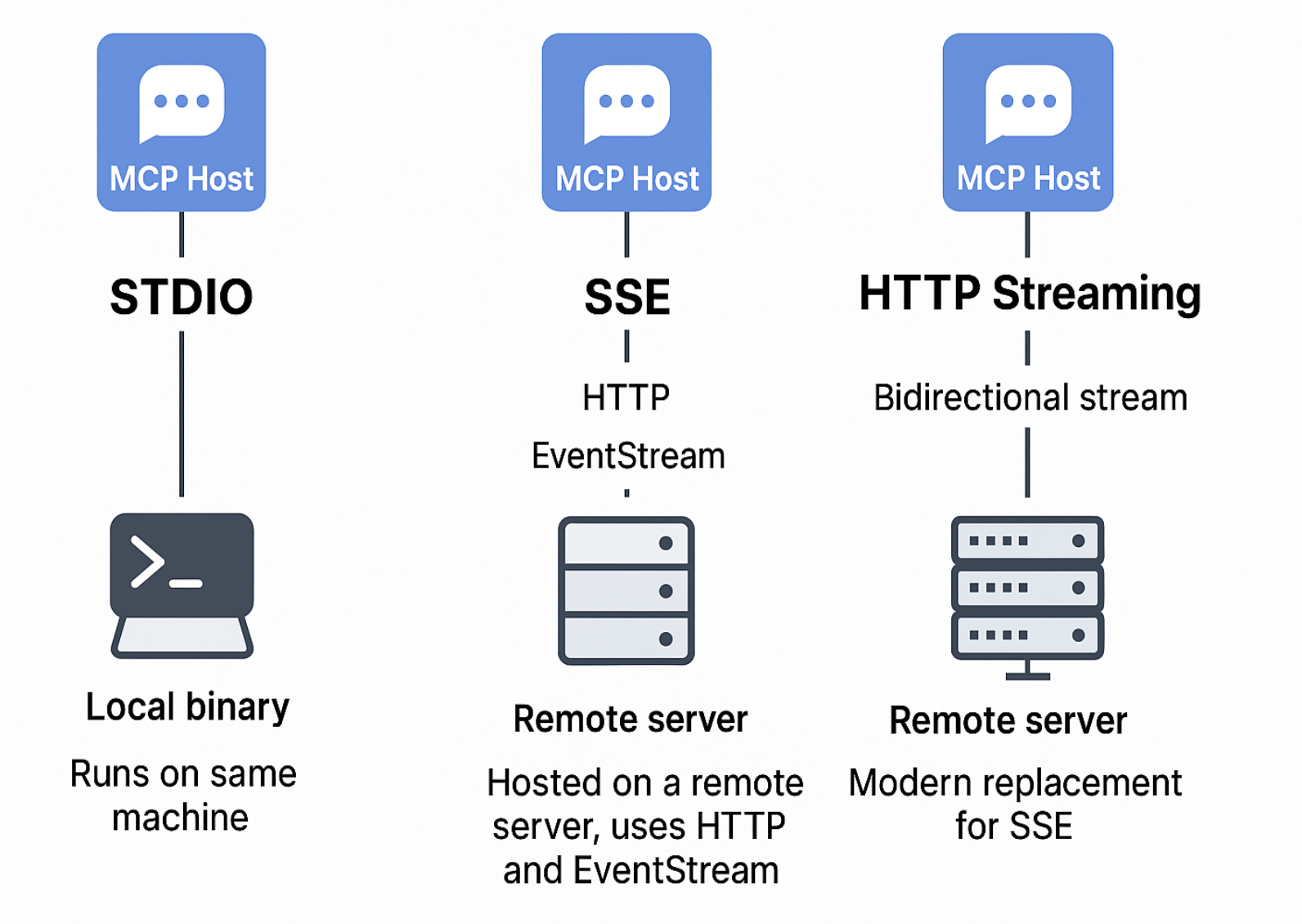
Large Language Models (LLMs) like GPT-4, Claude, and Mistral appear to produce intelligent responses — but the magic lies in how they consume and interpret context. Understanding what goes into an LLM's context and how it shapes output is critical for developers, researchers, and product designers working with generative AI.
This post explores the components of context, how it's structured, how it's limited, and how advanced use cases like tool usage and retrieval-augmented generation (RAG) interact with it.
What Is Context in an LLM?
"Context" refers to the entire input that the model sees in a single request. It includes:
- System instructions (e.g., "You are a helpful assistant")
- Memories (summaries of important facts from prior interactions)
- Conversation history (previous user/assistant messages, usually the latest or "current chat")
- Current user query - this is the prompt or question the user is asking
- External knowledge if an assiant is using retrieval-augmented generation (RAG) to pull in external knowledge
- Tools responses - if the model is using tools, like OpenAI's function calling and tools were called in the conversation
- Tool definitions - if tools/functions are available. List of tools and their function signatures are part of the context.
All of this input is serialized and tokenized, forming the request that the model uses to generate its response.
If a user enters a short message like "What is the weather today?", the context can be much longer than the message itself. The model will consider the system prompt, any memories, any relevant conversation history, any available tools, and any external knowledge before generating a response.
What Is a Context Window?
The context window is the maximum number of tokens a language model can consider at once. It defines how much information (instructions, messages, documents, etc.) can fit into a single interaction.
Different models support different context window sizes:
- GPT-3.5: 4,096 tokens
- GPT-4: 8,192 tokens
- GPT-4-turbo: 128,000 tokens
- Claude 2: 100,000 tokens
- Claude 3 Opus: 200,000+ tokens
If a request exceeds the model’s context limit, one of several things will happen (depending on the client or SDK used):
- The request may be rejected with a "context length exceeded" error.
- The oldest messages or parts of the context may be truncated.
- Early system prompts or memory data may be dropped first.
It is the responsibility of the developer or orchestration layer to keep the total context size under the model’s limit, often by trimming, summarizing, or chunking content intelligently.
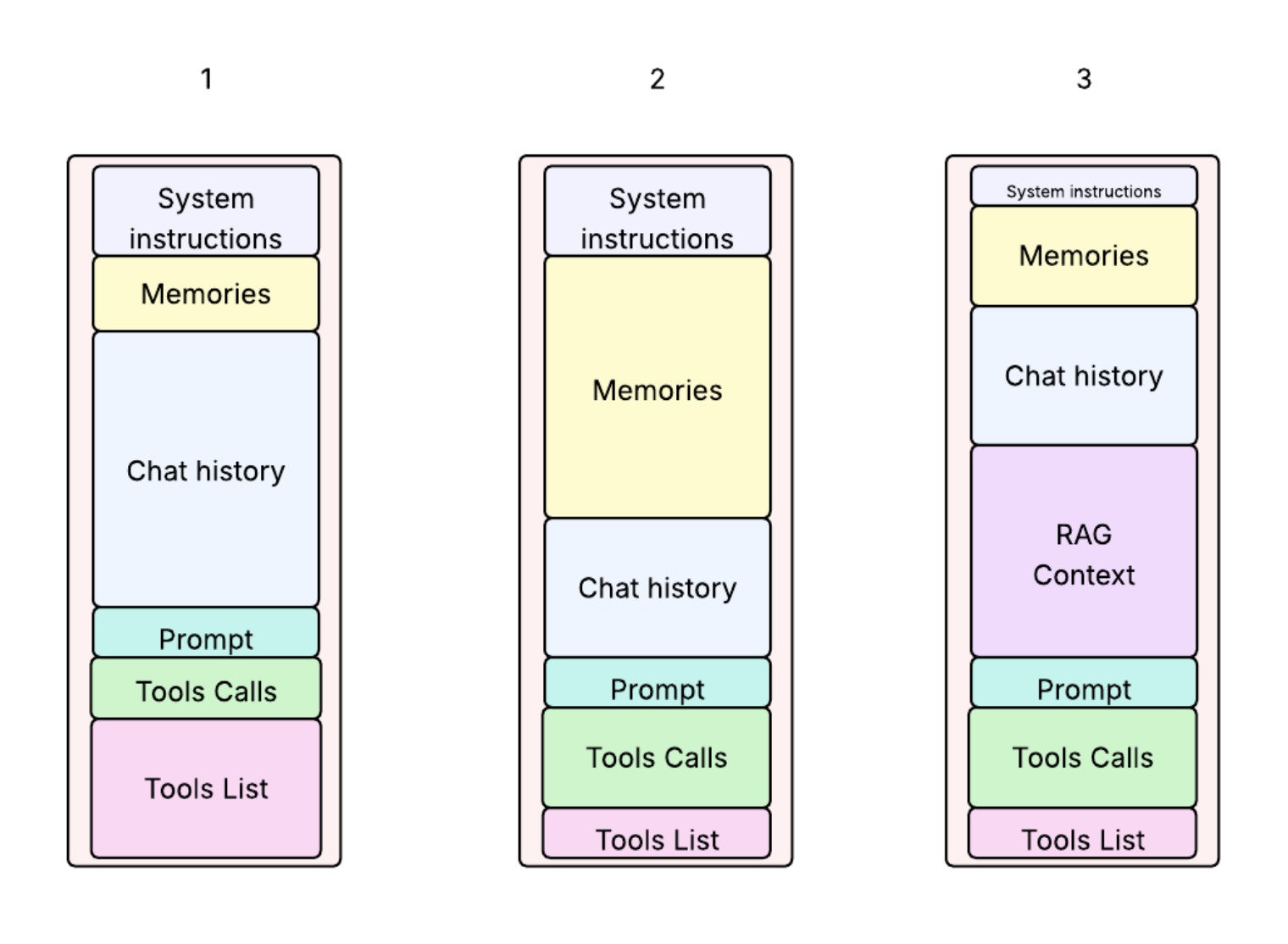
Components of the Context Window
1. System Prompt
A special instruction prepended to the conversation, used to set behavior or tone. Example:
{ "role": "system", "content": "You are a helpful assistant." }
2. Memories
Some systems extract and distill relevant long-term knowledge (facts, preferences, user traits) from previous conversations. These are typically added near the beginning of context, often using the system role or a custom marker like:
{ "role": "system", "content": "Memory: The user is studying for the bar exam and prefers concise answers." }
Alternatively, some implementations place memories under a custom memory role (non-standard) or append them to the user prompt with a label like "Important facts: ..." depending on model behavior and API support.
You can read more about memory in LLMs in the Implementing AI Chat Memory with MCP post.
3. Conversation History
The back-and-forth between the user and the assistant, typically encoded like this:
{ "role": "user", "content": "How do I cook rice?" },
{ "role": "assistant", "content": "Use a 2:1 water-to-rice ratio..." }
4. Current User Prompt
This is the new question or input being added to the conversation.
5. External Knowledge (RAG)
Retrieval-Augmented Generation (RAG) is a technique used to enhance an LLM’s ability to answer questions or generate content based on up-to-date or domain-specific information. Instead of relying solely on the model's pre-trained knowledge, RAG fetches relevant documents from an external source — such as a search engine, vector database, or custom corpus — and injects them into the prompt context.
This enables the model to reason over fresh, private, or otherwise unknown content without retraining. The retrieved documents are usually embedded into the user message along with the user's actual question, like so:
{ "role": "user", "content": "Context:
- Doc 1: ...
- Doc 2: ...
Question: What is X?" }json
{ "role": "user", "content": "Context:\n- Doc 1: ...\n- Doc 2: ...\n\nQuestion: What is X?" }
6. Tool Calls and Results
In models that support tools (e.g., OpenAI, Claude), tool definitions and results can be passed as structured content in the context.
Often AI tools use MCP (Model Context Protocol) to work with tools. The tool call is structured like this:
{ "role": "assistant", "tool_calls": [{"name": "get_weather", "arguments": {"location": "London"}}] }
The tool response is structured like this:
{ "role": "tool", "name": "get_weather", "content": "It is 16\u00b0C and sunny in London." }
(the role could be tool or user depending on the model and API).
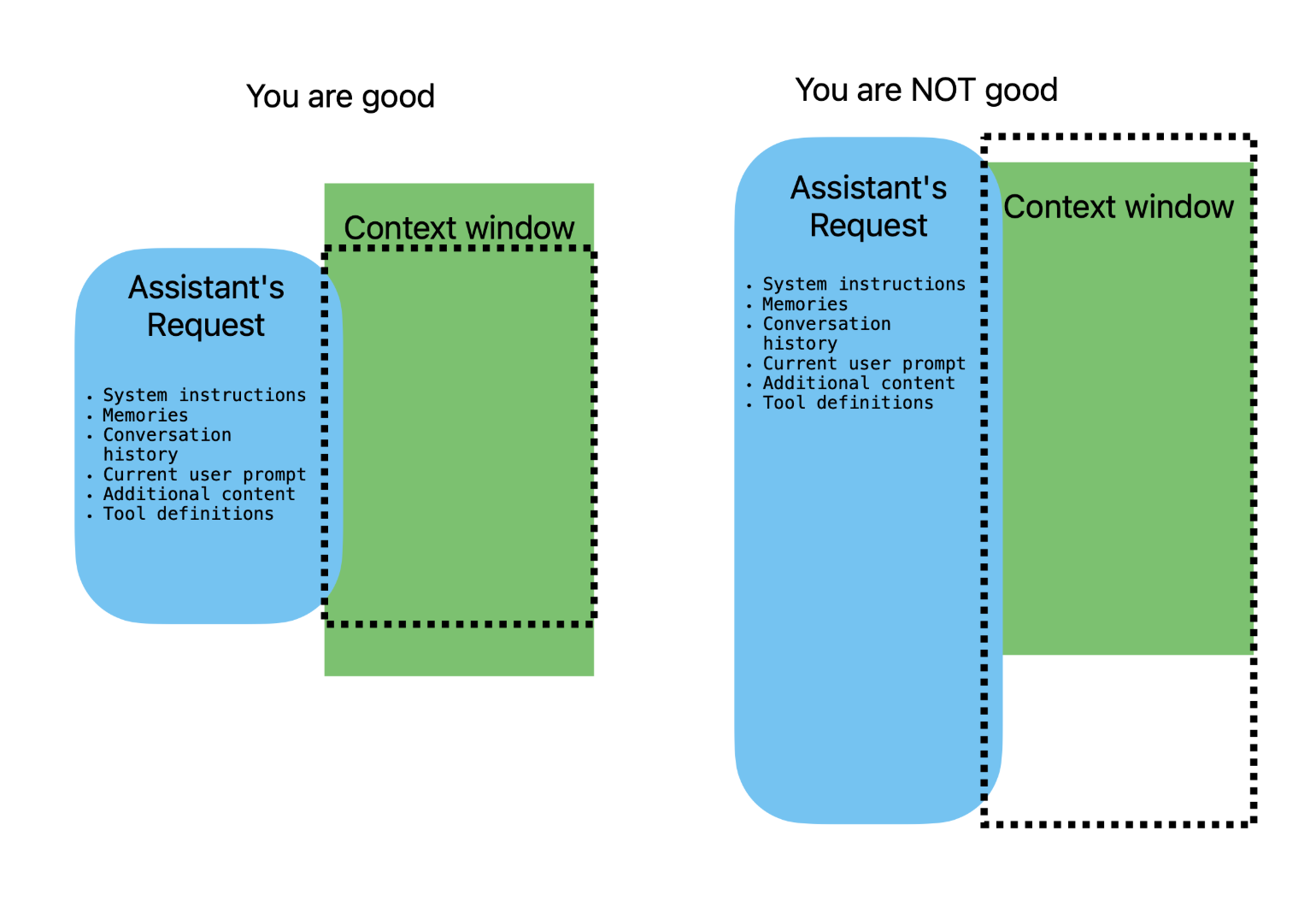
To fit the context window - this is where the magic happens
You can not just throw everything into the context and expect the model to handle it. The context size is limited and every AI assistant tool should care about this.
The data you include in the context , the balance between the system prompt, memories, conversation history, and external knowledge is crucial for the model to generate relevant and coherent responses. This balance is really the key to successful AI assistant design.
If your context exceeds this limit:
- Old messages may be truncated.
- Early system prompts might be dropped.
- RAG content may be cut.
Efficient prompt design and message trimming strategies are essential to stay within the limit.
The figure demonstrates how the context can be balanced. Because it is limited there is always a trade-off between the system prompt, memories, conversation history, and external knowledge.
Tokenization: Counting the Cost
A context window is measured in tokens, not characters or words.But our data are usually in words. Even more, we operate with a JSON document.
How to know how many tokens we have before we send the request?
Text is tokenized (broken into sub-word units). A rough rule:
- 1 token ≈ 0.75 words (English)
For example:
- "Hello, world!" → 3 tokens
If you need exact numbers, you can estimate or measure token count using tools like OpenAI's tiktoken or HuggingFace's transformers.
This is the simple Python code to count tokens:
import tiktoken
# Choose your model
model_name = "gpt-3.5-turbo"
# Get encoding for the model
encoding = tiktoken.encoding_for_model(model_name)
# Your text prompt
prompt = "Once upon a time in a world far, far away..."
# Encode the text to tokens
tokens = encoding.encode(prompt)
# Count tokens
print(f"Token count: {len(tokens)}")
Context Compression and Memory Strategies
When context is too long:
- Truncate old messages
- Summarize history
- Embed and retrieve previous chunks (RAG)
Some architectures implement episodic memory or long-term memory that allows persistence beyond the single prompt window.
Tool Use and Context
If tools are enabled, the list of tools and their function signatures are part of the context. The model decides whether to invoke a tool. If a tool is called, the output is injected into the context before the next LLM response.
Example:
{ "role": "assistant", "tool_calls": [{"name": "get_weather", "arguments": {"location": "London"}}] }
Then:
{ "role": "tool", "name": "get_weather", "content": "It is 16\u00b0C and sunny in London." }
RAG and Context
RAG extends the model’s knowledge by injecting retrieved content into the prompt. Usually, the retrieved text is placed in the user message, just before the actual question.
This allows the LLM to reason over fresh or private data without fine-tuning.
Best Practices for Managing Context
- Keep system prompts concise but clear
- Trim history carefully, prioritizing recent or relevant turns
- Label RAG data (e.g., "Context:", "Relevant Documents:")
- Limit RAG injection to top 2-5 documents
- Measure token count before sending
- Use structured memory injection for long-term relevance
Conclusion
Context is the lifeblood of an LLM interaction. It's how the model "knows" what’s happening, what’s been said, and what tools or information are available. Designing, managing, and optimizing context is key to building powerful, reliable AI systems.
Understanding the structure and limitations of context lets you go beyond prompting — and into true prompt engineering.
The context structure and balance is one of secrets of success in AI assistant design. It is not easy to create own models, this is what we do not control. But we can control the context and how we use it.