Великі мовні моделі (LLM), такі як GPT-4, Claude, Mistral та інші, здаються розумними у своїх відповідях — але справжня магія полягає в тому, як вони сприймають і інтерпретують контекст. Розуміння того, що входить у контекст LLM і як це впливає на результат, критично важливе для розробників, дослідників і дизайнерів продуктів, які працюють із генеративним ШІ.
У цій публікації я хочу дослідити складові контексту, його структуру, обмеження та взаємодію з найбільш поширеними сценаріями використання, такими як використання інструментів (Tools, MCP) і включення додаткових знань з Retrieval-Augmented Generation (RAG).
Що таке контекст у LLM?
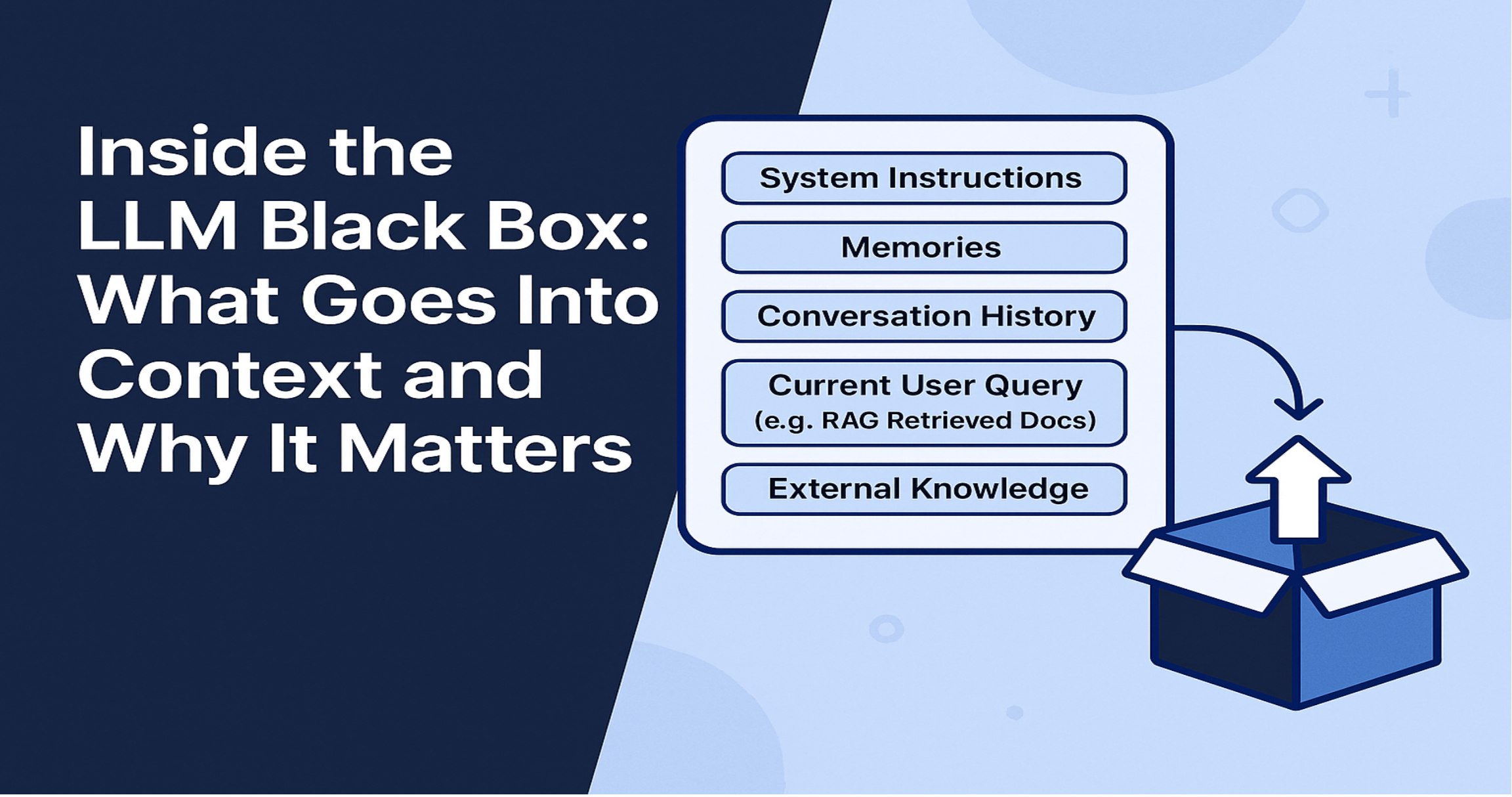
Контекст — це весь вхід, який модель бачить в одному запиті. Він включає:
- Системні інструкції (наприклад, "Ти — корисний асистент. Відповідай на питання користувача так, ніби ти Дональд Трамп.")
- Спогади - перелік важливих фактів із попередніх взаємодій, стиснена коротка версія попередніх розмов.
- Історію розмови - попередні повідомлення користувача/асистента, зазвичай останні або "поточні" чати.
- Поточний запит користувача — це те, що він питає зараз. Це сам текст, який користувач вводить у чат.
- Зовнішні знання (якщо використовується RAG)
- Відповіді інструментів — якщо модель використовує інструменти (напр., функції OpenAI або MCP сервери)
- Дані про інструменти — список доступних інструментів та їх сигнатури
Усе це серіалізується і токенізується, утворюючи запит, на основі якого модель генерує відповідь.
І крім цієї інформації немає більше нічого, лише те, що закодовано в самій моделі і цей запит.
Що таке вікно контексту?
Вікно контексту — це максимальна кількість токенів, яку модель може обробити за один раз. Воно визначає, скільки інформації (інструкцій, повідомлень, документів тощо) може поміститися у взаємодії.
Розміри вікна для різних моделей:
- GPT-3.5: 4,096 токенів
- GPT-4: 8,192 токени
- GPT-4-turbo: 128,000 токенів
- Claude 2: 100,000 токенів
- Claude 3 Opus: понад 200,000 токенів
Існує тенденція до збільшення розміру вікна контексту. Нові моделі переважно мають більше токенів у вікні контексту.
Якщо запит перевищує ліміт:
- Він може бути відхилений з помилкою “перевищено довжину контексту”
- Частина запиту може бути просто відкинута (або початок, або кінець)
- Перші системні інструкції або спогади можуть бути видалені
Відповідальність за дотримання ліміту несе розробник або шар оркестрації — через обрізання, резюмування або поділ вмісту.
Компоненти контексту
1. Системна інструкція
Інструкція, що встановлює поведінку асистента:
{ "role": "system", "content": "You are a helpful assistant. Respond to a user like you were Donald Trump." }
Це стандарт для більшості LLM API. Часто прихована від користувача.
2. Спогади
Системи можуть зберігати довготривалі знання, як-от:
{ "role": "system", "content": "Memory: The user is studying for the bar exam and prefers concise answers." }
Іноді зберігаються під власною роллю або у вигляді підписаних фактів у запиті користувача.
Спогади не є стандартом. Їх можна організовувати по різному. Це не є обов’язковою частиною контексту, і модель LLM не відповідає за організацію памʼяті..
Я описав як можна працювати з памʼяттю AI асистента у статті Implementing AI Chat Memory with MCP.
3. Історія розмови
Діалог між користувачем і асистентом:
{ "role": "user", "content": "How do I cook rice?" },
{ "role": "assistant", "content": "Use a 2:1 water-to-rice ratio..." }
Зазвичай найдовша частина контексту, що допомагає моделі розуміти поточний стан розмови.
Фактично, це попередні запитання та відповіді між користувачем і асистентом. Здебільшого, лише поточний чат. Повідомлення передаються в контекст "як є". Тобто без скорочення або резюмування.
4. Поточний запит користувача
Це є сам текст, який користувач вводить у чат. Наприклад:
{ "role": "user", "content": "Write a poem about what we talked about with you." }
Можна назвати його головною частиною контексту. Переважно це одна з найкоротших частин контексту. Але для моделі ця частина контексту не є чимось особливим. Вона просто передається в контекст, як і всі інші частини.
5. Зовнішні знання (RAG)
RAG дозволяє LLM використовувати свіжі або специфічні знання. Те, що не було в базі знань на яких модель навчалася. На практиці, це власні дані компаній або документи, які витягуються з зовнішніх джерел (пошукові системи, векторні бази даних тощо) і вставляються у запит.
Організація RAG може бути різною, як і отримання даних з бази даних. В кінцевому результаті, дані отримані зовні вставляються у контекст, зазвичай, перед запитом користувача:
{ "role": "user", "content": "Context:\n- Doc 1: ...\n- Doc 2: ...\n\nQuestion: What is X?" }
6. Виклики інструментів і результати
Підтримка інструментів реалізується через виклики та відповіді. Не всі моделі підтримують інструменти, але якщо так, то їх визначення та результати можуть бути передані у контекст.
Підтримка інструментів зараз переважно реалізується через MCP (Model Context Protocol). Виклик інструменту виглядає так:
- Модель замість "звичайної текстової" відповіді відповідає "очікую виклик інструмента з такими параметрами"
- Асистент викликає інструмент, отримує результат і додає відповідь назад в історію розмови (у контекст).
- Асистент знову робить запит до ЛЛМ вже з результатом інструмента.
- Отримується остаточна відповідь, або модель знову хоче виклик інструмента, тоді процес повторюється.
- Далі повідомлення з вимогою моделі про виклик інструмента і відповідь інструмента можуть бути видалені з історії.
{ "role": "role", "content": "What is the weather in London?" }
{ "role": "assistant", "content": "I will check the weather for you." }
{ "role": "assistant", "tool_calls": [{"name": "get_weather", "arguments": {"location": "London"}}] }
{ "role": "tool", "name": "get_weather", "content": "It is 16°C and sunny in London." }
{ "role": "assistant", "content": "The weather in London is 16°C and sunny. This is the great weather!" }
Для того щоб інструмент міг викликатися моделлю він має бути описаний у контексті. Це окремий розділ в структурі контексту.
І тут виникає проблема - якщо у вас багато інструментів, використання вікна контексту може бути неефективним.
Як вмістити дані у вікно контексту. Баланс вирішує все.
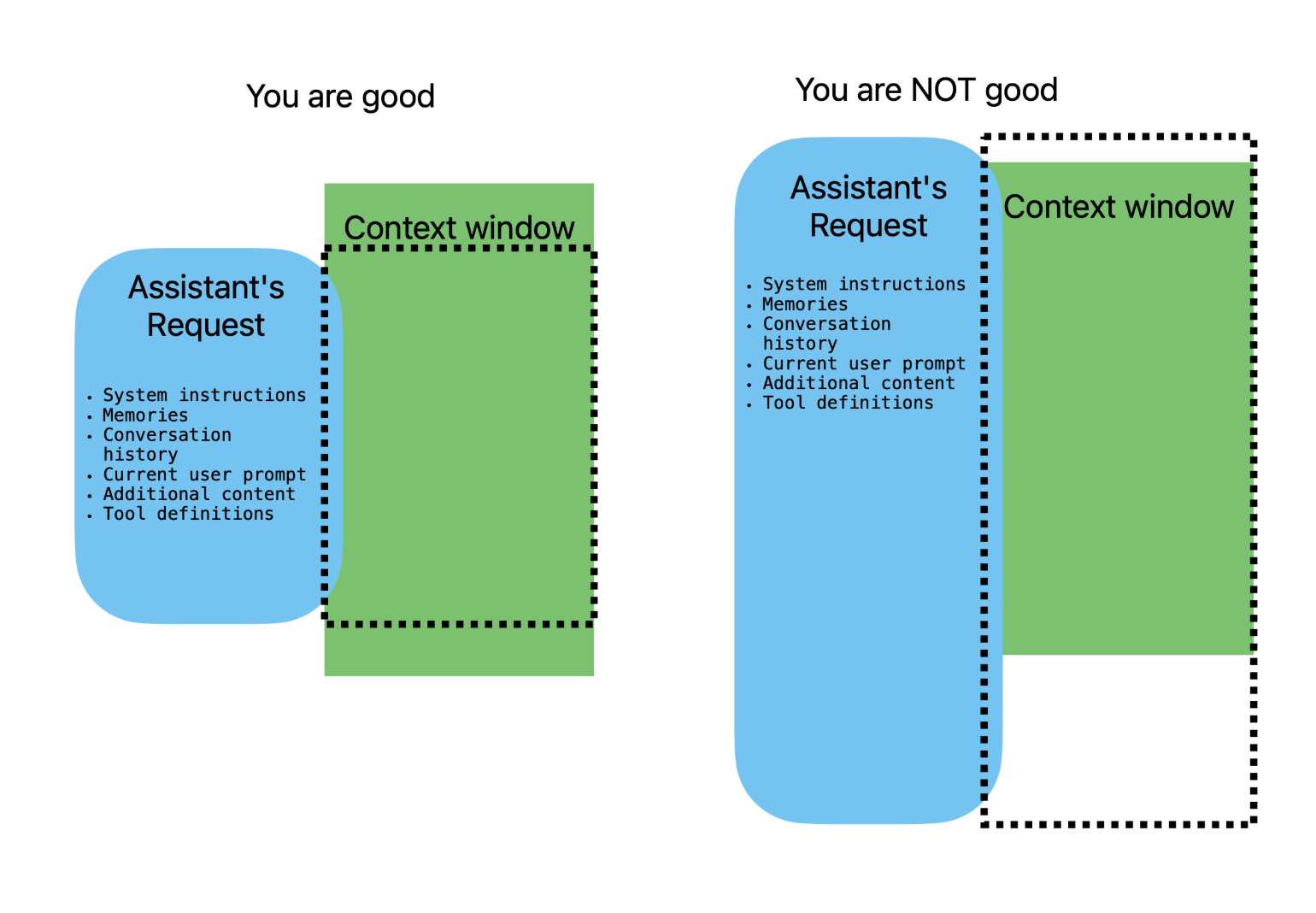
Неможливо просто передати до ЛЛМ все що хочеш — контекстне вікно обмежене. Кожен AI асистент повинен дбати про це.
Дані, які ви включаєте в контекст — баланс між системою підказкою, памʼяттю, історією розмови, зовнішніми знаннями інтеграцією інструментів — мають вирішальне значення для того, щоб модель генерувала доречні й узгоджені відповіді. Цей баланс насправді є ключем до успішного проєктування AI-асистента.
Ефективне проєктування підказок і стратегії обрізання повідомлень є критично важливими для того, щоб залишатися в межах ліміту.
На схемі показано, як можна збалансувати контекст. Оскільки він обмежений, завжди існує компроміс між системним підказом, памʼяттю, історією розмови та зовнішніми знаннями.
Пошук цього балансу є критично важливим для створення ефективного AI-асистента.
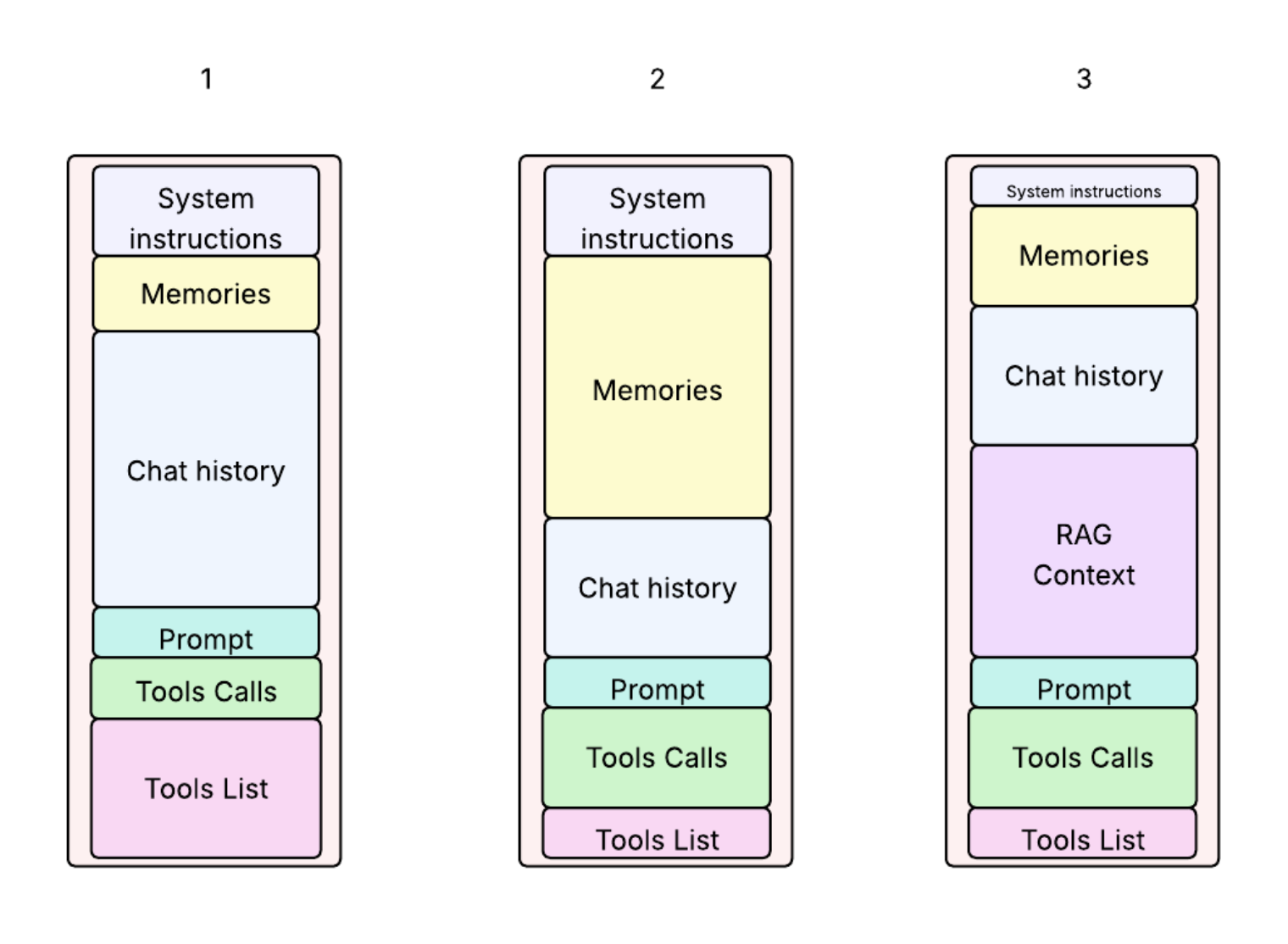
Приклади використання контексту
- Малюнок 1: Довга розмова — скоро потрібно буде обрізати старі повідомлення. Також підключено забагато інструментів.
- Малюнок 2: Великий обсяг спогадів — асистент пам’ятає багато фактів про користувача, є декілька викликів інструментів.
- Малюнок 3: RAG — більшість контексту займають зовнішні документи.
Токенізація: Вартість обчислень
Вікно контексту вимірюється в токенах, а не в символах чи словах. Але наші дані зазвичай подаються у вигляді слів. Більше того, ми працюємо з JSON-документом.
Як дізнатися, скільки токенів ми маємо перед тим, як надіслати запит?
Текст перед обробкою токенізується (розбивається на підслова або фрагменти слів).
Грубе правило для англійської мови: 1 токен ≈ 0.75 слова
Приклад:
"Hello, world!" → 3 токени
Якщо вам потрібна точна кількість токенів, ви можете оцінити або виміряти її за допомогою таких інструментів, як:
- tiktoken від OpenAI
- transformers від HuggingFace
Ці інструменти допоможуть вам точно порахувати кількість токенів у тексті або навіть у структурованих даних, таких як JSON.
Python-приклад підрахунку токенів:
import tiktoken
# Choose your model
model_name = "gpt-3.5-turbo"
# Get encoding for the model
encoding = tiktoken.encoding_for_model(model_name)
# Your text prompt
prompt = "Once upon a time in a world far, far away..."
# Encode the text to tokens
tokens = encoding.encode(prompt)
# Count tokens
print(f"Token count: {len(tokens)}")
Стиснення контексту і стратегії пам’яті
Якщо ваш контекст занадто довгий, ви можете:
- Відкинути давніші повідомлення з останніх розмов (розуміючи, що дані можуть втратитися)
- Резюмування історії, тобто використання додаткових інструментів для скорочення тексту, для виділення основних фактів та ін.
- Використання RAG. Тобто, перенести дані в окрему базу даних, а потім витягувати їх за допомогою векторного пошуку та вставляти в контекст лише найбільш релевантні дані.
- Обмеження кількості інструментів
- Довготривала пам’ять (епізодична або збережена)
Інструменти й контекст
Якщо інструменти увімкнені, список інструментів і їхні сигнатури (вхідні параметри) включаються в контекст. Модель самостійно вирішує, чи викликати інструмент. Якщо інструмент викликається, його результат додається до контексту перед наступною відповіддю LLM.
Я не знайшов чітких рекомендацій щодо того, скільки інструментів оптимально використовувати в одному AI-агенті. Але точно не варто використовувати їх надто багато. Це пов’язано з кількома проблемами:
- Розмір контексту: кожен інструмент і його опис займає місце в контекстному вікні.
- Навігація моделі: можна припустити, що чим більше інструментів, тим складніше моделі обрати правильний. Це може знизити ефективність і точність викликів.
Тому варто обирати лише ті інструменти, які справді потрібні для задач, які розвʼязує агент.
Це особливо зараз, коли появився протокол MCP (Model Context Protocol) для роботи з інструментами. Ентузіасти публікують сотні нових серверів MCP, які реалізують різні інструменти. Існує спокуся підключити все і одразу. Але досвід показує, що це не завжди найкраще рішення.
RAG і контекст
RAG розширює знання моделі, вставляючи витягнутий текст перед питанням. Це дозволяє уникнути перенавчання.
В плані балансу контексту, документи вибрані з RAG можуть займати багато місця. Тому важливо обмежити кількість документів до 2–5 найбільш релевантних. Тобто, використовувати рішення, які дозволяють обирати найбільш релевантні документи для запиту.
Кращі практики управління контекстом
- Системні інструкції мають бути чіткими й короткими
- Системні інструкції мають бути на початку запиту завжди (поширена помилка — їх видаляти коли обрізається історія)
- Історію обрізати обережно — залишати актуальне. Часто, зменшення історії виконується з допомогою додаткових інструментів, які резюмують історію.
- Структурована пам’ять для важливих фактів. Отримується через аналіз всіх запитів і відповідей.
- Обмежувати RAG до 2–5 документів, контролювати загальний розмір та якість документів
- Порахувати токени перед відправленням
- Уникати перевантаження інструментами. Використовувати лише ті, які дійсно потрібні для задачі
Що варто пам’ятати
- Ви відповідаєте за розмір контексту
- LLM не обрізають та не оптимізують запит автоматично
- Системні інструкції мають залишатися, навіть якщо історію обрізано
Висновок
Контекст є ключовим елементом ефективної взаємодії з LLM. Від структури контексту залежить ефективність роботи моделі, корисність її відповідей. Дизайн, управління й оптимізація контексту — ключ до створення ефективного ШІ асистента.
Розуміння структури й обмежень дає змогу перейти від простого промптування до справжньої інженерії запитів.
Ми, прості інженери, не можемо самі створювати ЛЛМ моделі так, щоб вони були кращі ніж у конкурентів. Це потребує значних ресурсів. Але ми можемо шукати оптимальну структуру контексту запиту до ЛЛМ щоб отримати найкращі результати в наших асистентів, чи навіть в майбутньому AGI.

