As large language models (LLMs) find real-world use, the need for flexible ways to connect them with external tools is growing. The Model Context Protocol (MCP) is an emerging standard for structured tool integration.
Most current tutorials focus on STDIO-based MCP servers (Standard Input/Output), which must run locally with the client. But MCP also supports SSE (Server-Sent Events), allowing remote, asynchronous communication over HTTP—ideal for scalable, distributed setups.
In this article, we’ll show how to build an SSE-based MCP server to enable real-time interaction between an LLM and external tools.
For this example, I’ve chosen the “Execute any command on my Linux” tool as the backend for the MCP server. Once connected to an LLM, this setup enables the AI to interact with and manage a Linux instance directly.
Additionally, I’ll demonstrate how to add a basic security layer by introducing authorization token support for interacting with the MCP server.
Building the MCP server (with SSE transport)
To build the server, I used the Python library MCP Python SDK
You can find many examples of MCP servers created with this SDK, but most of them use the STDIO transport. This means the MCP server must be installed locally on the same machine as the MCP client.
Here, we want to take a different approach—a server that can run remotely, essentially as a SaaS service. To achieve this, we need a proper transport layer. For my implementation, I used the FastAPI framework.
Below is the basic working code (mcp_server.py):
from mcp.server.fastmcp import FastMCP
from fastapi import FastAPI
app = FastAPI()
mcp = FastMCP("Server to manage a Linux instance")
@mcp.tool()
def cli_command(command: str, work_dir: str | None = "") -> str:
"""
Execute command line cli command on the Linux server.
Arguments:
command - command to execute.
work_dir - workdir will be changed to this path before executing the command.
"""
response = ".... execute the command and get output"
return response
app.mount("/", mcp.sse_app())In your python environment you will need to install mcp and fastapi packages.
Note. This MCP server supports SSE transport but also it can work as STDIO server too! See below how to use it in both ways.
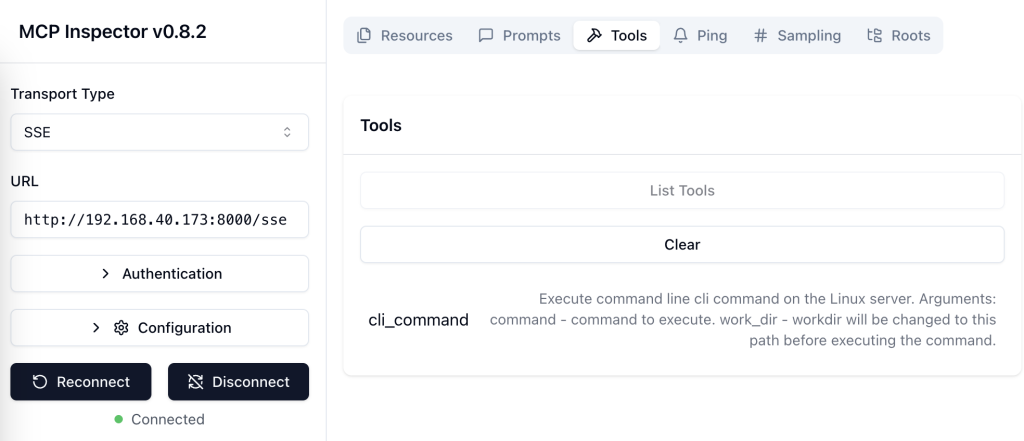
Testing the MCP SSE server
The MCP Python SDK has a nice tool build in it – MCP Inspector. As i understand this tool can be installed independently too. The tool can be used to verify quickly if your MCP server works.
From your project directory (where you have environment with mcp package installed) run following:
mcp dev mcp_server.pyIt will print the endpoint for web interface like http://127.0.0.1:6274 . Open it in a browser.
You are able to choose a way how to connect to a server. First, try STDIO. For me it shows the command “uv” because i used uv to create my environment. I didn’t modify anything here, just clicked “Connect”. Then “Tools” and “List tools”.
The tool “cli_command” should be visible.
Now “Disconnect”. And before to connect in SSE mode we need to start our local MCP SSET server.
In your python project directory run:
fastapi dev mcp_server.py --host 0.0.0.0Note. The `–host 0.0.0.0` is optional. You must not use it if you execute this on same machine. In my case i executed the server on another Linux machine and my MCP inspector was on a mac, so i had to be able to connect to the server and it had to accept connections from remote clients.
The default port for Fastapi is 8000 so, your server is now on the endpoint http://localhost:8000/sse (or http://some_host_or_ip:8000/sse)
In your MCP Inspector choose Transport SSE , URL http://some_host_or_ip:8000/sse and click Connect.
And then click “Tools” again. You should see same tool cli_command.
Adding the Authentification support
In practice, we’ll want some security measures if this kind of application is accessible over a network. After all, it’s a SaaS service and should be protected to the same extent as any other SaaS API.
To achieve this, I added support for the Authorization HTTP header.
Unfortunately, I couldn’t find a clean way to implement this. While FastMCP’s syntax looks similar to FastAPI, it lacks support for features like dependencies, accessing the Request object, etc.
As a result, I had to use a workaround involving a global variable—admittedly not the best practice.
Here is the final code:
from mcp.server.fastmcp import FastMCP
from fastapi import FastAPI
from .authmanager import AuthManager
from .worker import Worker
# Global variable for a token
auth_token = ""
app = FastAPI()
mcp = FastMCP("Server to manage a Linux instance")
@app.middleware("http")
async def auth_middleware(request: Request, call_next):
auth_header = request.headers.get("Authorization")
if auth_header:
# extract token from the header and keep it in the global variable
global auth_token
auth_token = auth_header.split(" ")[1]
response = await call_next(request)
return response
@mcp.tool()
def cli_command(command: str, work_dir: str | None = "") -> str:
"""
Execute command line cli command on the Linux server.
Arguments:
command - command to execute.
work_dir - workdir will be changed to this path before executing the command.
"""
# We require each request to have the auth token
AuthManager().verify_token(auth_token)
return Worker().run_command(command, work_dir)
app.mount("/", mcp.sse_app())In fact, the token needs to be checked inside each tool method, which isn’t ideal.
Initially, I tried raising an exception directly from the middleware, but the results weren’t great. FastAPI produced some messy error output, and the client didn’t receive a proper response.
To test that the auth token is being received correctly, use the MCP Inspector and the Authentication input field. Add your code to verify the token accordingly.
Confirm it works with LLM
Now for the most interesting part — how can we use our MCP server with an LLM if it’s running as a SaaS on a remote host?
As of April 2025, the answer is: no popular AI chat tool supports this. Cloud Desktop only supports STDIO-based MCP tools. ChatGPT doesn’t support MCP at all (though they’ve announced plans to support it soon).
The only way I could test this was with a small tool called “mcphost“, but even then, it wasn’t straightforward — I had to modify the tool myself.
You can install the tool using:
go install github.com/mark3labs/mcphost@latestHowever, it originally supported only STDIO. I made some changes to add SSE (Server-Sent Events) support as well.
Update: I submitted a PR to the mcphost repository, and it’s now approved. So I expect this functionality will be available in the next release. But, that PR didn’t have authentication support. I plan to submit another PR to address that.
So, after some modification, this tool finally allowed me to connect an LLM to my MCP server.
I’ve created the config file
{
"mcpServers": {
"linux_server": {
"command": "sse_server",
"args": [
"http://192.168.40.173:8000/sse",
"my-secret-token"
]
}
}
}And i executed the command
./mcphost --config ./mcp.json --model ollama:qwen2.5:3bBefore to exeucte this it is needed to install ollama locally and pull the model. I have used the model qwen2.5:3b. It is small and works fast. But there are better models then this.
Not each model supports tools. On the ollama directory there is special filter for models supporting tools/MCP.
And voila, here is the result
2025/04/11 20:47:38 INFO Model loaded provider=ollama model=qwen2.5:3b
2025/04/11 20:47:38 INFO Initializing server... name=linux_server
2025/04/11 20:47:38 INFO Server connected name=linux_server
2025/04/11 20:47:38 INFO Tools loaded server=linux_server count=1
You: Can you confirm you have access to the linux? run some test command
Assistant:
2025/04/11 20:48:00 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
The command was executed successfully on the Linux server. The output was "Test message from Linux server". Everything went as expected with a return code of 0, indicating success.
You: Can you detect what distro is that?
Assistant:
2025/04/11 20:48:15 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
The Linux distribution detected is Ubuntu 24.04.2 LTS, codenamed "Noble Numbat".
You: What is the desktop system there?
Assistant:
2025/04/11 20:48:36 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
Based on the desktop environment files found in /usr/share/xsessions/, it appears that the system uses either Lubuntu, LXQt, or Openbox as its default
graphical session. This information can indicate that a display manager such as LightDM (default for Ubuntu) might be handling the login screen but not
having an xorg.conf file, which is common in environments using light-weight window managers like those found in LXQt or Openbox.
You: How busy is my linux server?
Assistant:
2025/04/11 21:20:29 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
2025/04/11 21:20:31 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
2025/04/11 21:20:33 INFO 🔧 Using tool name=linux_server__cli_command
Assistant:
Based on the uptime output, your Linux server has a current system load average of 0.03, which is relatively low and indicates that
your server is not currently very busy with tasks. The top command failed due to an unknown option when trying to retrieve CPU
usage information directly, so let's rely on this as our current load indication.
If you need more detailed monitoring data such as CPU utilization or memory usage, please let me know and I can assist further by
executing additional commands. Again, what was done here and how does it work
There is the Mac desktop with ollama installed and some model pulled to it.
Also, there is the Linux server. On that server we have started the MCP server (written with python) and it listens on the port accepting http requests.
Also, on the mac desktop we have the tool “MCP host”. It contains MCP client and it can work with LLMs. This tool connects LLM with the Linux over the MCP server.
Later, we will use Cloud Desktop or ChatGTP Desktop instead of our “mcphost”. I expect they will add support of this soon (i hope). So, to play with MCP servers we will not need additional tools to integrate all together.